この記事は Google Research ソフトウェア エンジニア、Liang-Chieh Chen、Yukun Zhu による Google Research Blog の記事 "Semantic Image Segmentation with DeepLab in TensorFlow" を元に翻訳・加筆したものです。詳しくは元記事をご覧ください。
セマンティック イメージ セグメンテーションとは、イメージ内のすべてのピクセルに「道路」、「空」、「人」、「犬」などといった意味のあるラベルを割り当てる処理のことです。これは、Pixel 2 および Pixel 2 XL スマートフォンのポートレート モードに搭載されている被写界深度を浅く見せる効果を合成によって作り出す機能や、モバイルによるリアルタイム動画セグメンテーションなど、さまざまな形で応用することができます。意味のあるラベルを割り当てるには、物体の輪郭をピンポイントで判別する必要があります。そのため、イメージレベルでの分類やバウンディング ボックスレベルでの検知などによる視覚エンティティ認識タスクよりも、はるかに厳密に位置を検出しなければなりません。
![]() 本日(*原文公開当時)は、私たちが誇る最新で最高のパフォーマンスを持つセマンティック イメージ セグメンテーション モデルである DeepLab-v3+ [1]*をオープンソースとしてリリースしたことをお知らせします。これは、TensorFlowを使って実装されています。今回のリリースには、最も正確な結果が得られるように、強力な畳み込みニューラル ネットワーク(CNN)バックボーン アーキテクチャ [2, 3] をベースに構築された DeepLab-v3+ モデルが含まれています。これは、サーバー側にデプロイすることを想定したものです。このリリースの一部として、TensorFlow モデルのトレーニングおよび評価用のコードと、セマンティック セグメンテーション処理のベンチマークである Pascal VOC 2012と Cityscapesを使ってトレーニングを済ませたモデルも公開しています。
本日(*原文公開当時)は、私たちが誇る最新で最高のパフォーマンスを持つセマンティック イメージ セグメンテーション モデルである DeepLab-v3+ [1]*をオープンソースとしてリリースしたことをお知らせします。これは、TensorFlowを使って実装されています。今回のリリースには、最も正確な結果が得られるように、強力な畳み込みニューラル ネットワーク(CNN)バックボーン アーキテクチャ [2, 3] をベースに構築された DeepLab-v3+ モデルが含まれています。これは、サーバー側にデプロイすることを想定したものです。このリリースの一部として、TensorFlow モデルのトレーニングおよび評価用のコードと、セマンティック セグメンテーション処理のベンチマークである Pascal VOC 2012と Cityscapesを使ってトレーニングを済ませたモデルも公開しています。
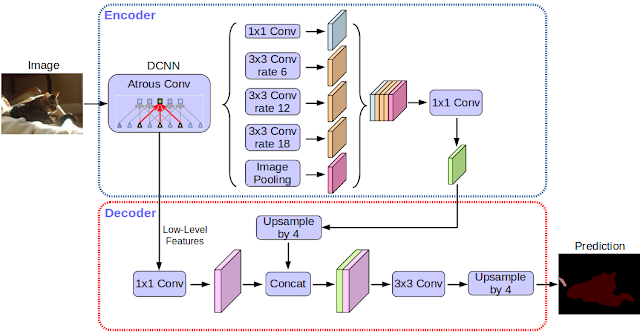
初めての DeepLab モデル [4] は、3 年前に誕生しました。それ以来、CNN の特徴抽出の改善、オブジェクト スケーリング モデルの向上、コンテキスト情報の正確な利用、トレーニング手続きの改善、さらに強力になったハードウェアとソフトウェアによって、改善が加えられた DeepLab-v2 [5] や DeepLab-v3 [6] が生まれています。DeepLab-v3+ は DeepLab-v3 を拡張したもので、シンプルかつ効果的なデコーダ モジュールが追加されており、特に物体の境界付近のセグメンテーション処理の精度が上がっています。さらに、Atrous 空間ピラミッド プーリング [5, 6] とデコーダ モジュールの両方に対し、深さ方向に畳み込みを分解する Depthwise Separable Convolutionを適用することにより、高速で強力なセマンティック セグメンテーション用エンコーダデコーダ ネットワークを実現しています。
![]() 畳み込みニューラル ネットワーク(CNN)をベースとした最新のセマンティック イメージ セグメンテーション システムは、手法、ハードウェア、データセットが進化したことにより、5 年前ですら想像できなかったレベルの精度に達しています。このシステムがコミュニティに広く公開されることで、学会や産業界の他のグループによる最新のシステムの再現や改善、新しいデータセットを使ったモデルのトレーニング、このテクノロジーを活用する新たなアプリケーションの構想などが推進されることを期待しています。
畳み込みニューラル ネットワーク(CNN)をベースとした最新のセマンティック イメージ セグメンテーション システムは、手法、ハードウェア、データセットが進化したことにより、5 年前ですら想像できなかったレベルの精度に達しています。このシステムがコミュニティに広く公開されることで、学会や産業界の他のグループによる最新のシステムの再現や改善、新しいデータセットを使ったモデルのトレーニング、このテクノロジーを活用する新たなアプリケーションの構想などが推進されることを期待しています。
謝辞
サポートと価値ある議論を提供してくれた Iasonas Kokkinos 氏、Kevin Murphy 氏、Alan L. Yuille 氏(DeepLab-v1 および -v2 の共著者)に感謝いたします。また、Mark Sandler 氏、Andrew Howard 氏、Menglong Zhu 氏、Chen Sun 氏、Derek Chow 氏、Andre Araujo 氏、Haozhi Qi 氏、Jifeng Dai 氏、そして Google Mobile Vision チームにも感謝を捧げます。
参考文献
* DeepLab-v3+ は、Pixel 2 のポートレート モードやリアルタイム動画セグメンテーションには利用されていません。投稿の中では、このタイプのテクノロジーで実現できる機能の例として触れられています。↩
Reviewed by Haruka Iwao, Developer Advocate, Google Cloud![]()
セマンティック イメージ セグメンテーションとは、イメージ内のすべてのピクセルに「道路」、「空」、「人」、「犬」などといった意味のあるラベルを割り当てる処理のことです。これは、Pixel 2 および Pixel 2 XL スマートフォンのポートレート モードに搭載されている被写界深度を浅く見せる効果を合成によって作り出す機能や、モバイルによるリアルタイム動画セグメンテーションなど、さまざまな形で応用することができます。意味のあるラベルを割り当てるには、物体の輪郭をピンポイントで判別する必要があります。そのため、イメージレベルでの分類やバウンディング ボックスレベルでの検知などによる視覚エンティティ認識タスクよりも、はるかに厳密に位置を検出しなければなりません。

初めての DeepLab モデル [4] は、3 年前に誕生しました。それ以来、CNN の特徴抽出の改善、オブジェクト スケーリング モデルの向上、コンテキスト情報の正確な利用、トレーニング手続きの改善、さらに強力になったハードウェアとソフトウェアによって、改善が加えられた DeepLab-v2 [5] や DeepLab-v3 [6] が生まれています。DeepLab-v3+ は DeepLab-v3 を拡張したもので、シンプルかつ効果的なデコーダ モジュールが追加されており、特に物体の境界付近のセグメンテーション処理の精度が上がっています。さらに、Atrous 空間ピラミッド プーリング [5, 6] とデコーダ モジュールの両方に対し、深さ方向に畳み込みを分解する Depthwise Separable Convolutionを適用することにより、高速で強力なセマンティック セグメンテーション用エンコーダデコーダ ネットワークを実現しています。
謝辞
サポートと価値ある議論を提供してくれた Iasonas Kokkinos 氏、Kevin Murphy 氏、Alan L. Yuille 氏(DeepLab-v1 および -v2 の共著者)に感謝いたします。また、Mark Sandler 氏、Andrew Howard 氏、Menglong Zhu 氏、Chen Sun 氏、Derek Chow 氏、Andre Araujo 氏、Haozhi Qi 氏、Jifeng Dai 氏、そして Google Mobile Vision チームにも感謝を捧げます。
参考文献
- Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation, Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, and Hartwig Adam, arXiv:1802.02611, 2018.
- Xception:Deep Learning with Depthwise Separable Convolutions, François Chollet, Proc. of CVPR, 2017.
- Deformable Convolutional Networks — COCO Detection and Segmentation Challenge 2017 Entry, Haozhi Qi, Zheng Zhang, Bin Xiao, Han Hu, Bowen Cheng, Yichen Wei, and Jifeng Dai, ICCV COCO Challenge Workshop, 2017.
- Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs, Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L. Yuille, Proc. of ICLR, 2015.
- Deeplab:Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs, Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L. Yuille, TPAMI, 2017.
- Rethinking Atrous Convolution for Semantic Image Segmentation, Liang-Chieh Chen, George Papandreou, Florian Schroff, and Hartwig Adam, arXiv:1706.05587, 2017.
* DeepLab-v3+ は、Pixel 2 のポートレート モードやリアルタイム動画セグメンテーションには利用されていません。投稿の中では、このタイプのテクノロジーで実現できる機能の例として触れられています。↩
Reviewed by Haruka Iwao, Developer Advocate, Google Cloud