[この記事は Shanee Nishry、ゲーム デベロッパーアドボケートによる Android Developers Blog の記事 "Game Performance: Data-Oriented Programming" を元に翻訳・加筆したものです。詳しくは元記事をご覧ください。]
CPU 性能を最大限に高め、ゲームを効率化し、よりスマートなコードでゲーム パフォーマンスを向上させるために役立つプログラミングの実例を紹介します。
データ指向プログラミングについて解説する前に、データ指向プログラミングによって解決できる問題や、プログラマーが陥りやすい落とし穴について説明します。
メモリ
プログラマーが最初に理解しておくべきことは、メモリは遅いということと、コーディングの仕方がメモリの利用効率に影響するということです。メモリ レイアウトや操作順序が非効率だと、CPU はメモリに対して待機したアイドル状態となり、処理を続行します。説明をわかりやすくするために、サンプルを使います。次の簡単なコード サンプルをご覧ください。
char data[1000000];// One Million bytes100 万バイトの配列が宣言され、1 バイトごとに反復処理が行われています。次に、そのコードが動作するハードウェアを表すために、少し変更を加えます。変更点は太字で示しています。
unsignedint sum =0;
for(int i =0; i <1000000;++i )
{
sum += data[ i ];
}
char data[16000000];// Sixteen Million bytes1600 万バイトを格納するように配列を変更しました。一度に 16 バイトずつスキップして 100 万バイトを反復しています。
unsignedint sum =0;
for(int i =0; i <16000000; i +=16)
{
sum += data[ i ];
}
同じ命令の数だけコードが変換され、実行される回数も同じであるため、一見パフォーマンスに影響はないように思われますが、そうではありません。こちらはその違いを表すグラフです。これは対数目盛で表されてますが、均等目盛りで表すと、普通のグラフでは表示しきれないほどパフォーマンスの違いは大きくなります。
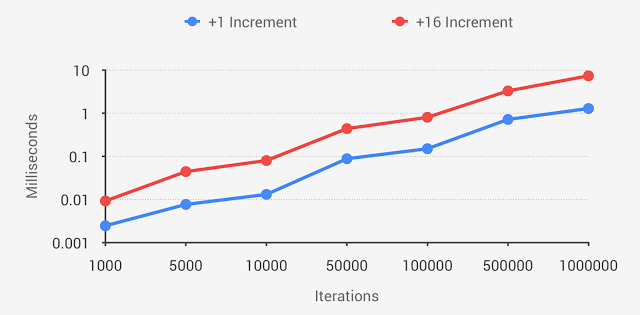
対数目盛のグラフ
一度に 16 バイトのループ スキップが実行されるように簡単な変更を加えたことによって、プログラムの速度は 5 倍遅くなります。1,000 バイトから 100 万バイトの反復処理におけるパフォーマンスの平均差異は 5 倍であり、最大で 7 倍まで拡大することもあります。この変更はパフォーマンスにおいて深刻です。
注:このベンチマークは、デスクトップ(Intel 5930K 3.50GHz CPU)、Macbook Pro Retina ラップトップ(2.6 GHz Intel i7 CPU)、Android Nexus 5 および Nexus 6 デバイスなど、複数のハードウェア構成で実行され、どのハードウェア構成でも同じような結果になりました。
コンパイラーによっては宣言時に配列をキャッシュに保存するため、テストを再現するには、ループが実行される前に、キャッシュからメモリを解放する必要があります。処理の仕組みについては、以下で説明します。
説明
CPU がどのようにしてデータにアクセスするかを理解すれば、前述のサンプルで行われた処理内容を簡単に説明できます。CPU は RAM のデータにはアクセスできません。CPU チップの近くにある、小さくて極めて高速なメモリラインであるキャッシュにデータをコピーする必要があります。プログラムが開始されると、CPU は配列の一部で命令を実行しますが、そのデータはまだキャッシュに存在しないため、キャッシュミスが発生し、データがキャッシュにコピーされるまで CPU は待機することになります。
説明をわかりやすくするために、16 バイトのキャッシュ サイズを L1 キャッシュ ラインと想定します。つまり、16 バイトは命令に対して要求されたアドレスからコピーされます。
最初のコードサンプルでは、プログラムは次に後続のバイトで処理を試みますが、最初のキャッシュミス後のキャッシュにすでにコピーされているため、処理はスムーズに継続されます。これは次の 14 バイトについても同様です。16 バイトの後は、最初のキャッシュミス以降、ループで別のキャッシュミスが発生し、CPU は次の 16 バイトをキャッシュにコピーして、再び処理対象のデータを待機します。
2 番目のコードサンプルでは、ループは一度に 16 バイトずつスキップしますが、ハードウェアは同じ処理を続けます。キャッシュはキャッシュミスが発生するたびに後続の 16 バイトをコピーするため、反復処理ごとにループでキャッシュミスがトリガーされ、CPU はそのたびにデータを待機するアイドル状態になります。
注:最近のハードウェアでは、フレームごとのキャッシュミスを回避するキャッシュ プリフェッチ機構が実装されていますが、プリフェッチを実行した場合でも、このサンプルテストでは帯域幅の使用量が増え、パフォーマンスが低下します。
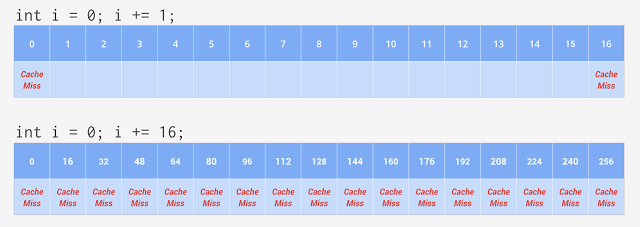
キャッシュ ラインが非常に小さい主な理由は、高速なメモリを作るにはコストがかかるためです。
データ指向設計
このようなパフォーマンスの問題を解決する方法は、キャッシュに合わせてデータを調整し、プログラムが継続してデータ全体を処理するように設計することです。これは、構造体の配列(AoS)の代わりに配列の構造体(SoA)にゲーム オブジェクトを整理し、予想されるデータを格納するために十分なメモリを事前に割り当てることで行えます。
たとえば、AoS レイアウトの単純な物理オブジェクトは次のようになります。
structPhysicsObjectこれは、C++ でオブジェクトを表す一般的な方法です。
{
Vec3 mPosition;
Vec3 mVelocity;
float mMass;
float mDrag;
Vec3 mCenterOfMass;
Vec3 mRotation;
Vec3 mAngularVelocity;
float mAngularDrag;
};
一方、SoA レイアウトを使用した場合は次のようになります。
classPhysicsSystemオブジェクトの位置を速度で更新する簡単な関数がどのように動作するかを比べてみましょう。
{
private:
size_t mNumObjects;
std::vector<Vec3> mPositions;
std::vector<Vec3> mVelocities;
std::vector<float> mMasses;
std::vector<float> mDrags;
// ...
};
AoS レイアウトの場合、関数は次のようになります。
voidUpdatePositions(PhysicsObject* objects,const size_t num_objects,constfloat delta_time )PhysicsObject がキャッシュに読み込まれますが、使用されるのは最初の 2 つの変数のみです。それぞれ 12 バイトなので、反復処理ごとに使用されるキャッシュ ラインの 24 バイトと等しくなり、Nexus 5 の 64 バイトのキャッシュ ラインでオブジェクトごとにキャッシュミスが発生されることになります。
{
for(int i =0; i < num_objects;++i )
{
objects[i].mPosition += objects[i].mVelocity * delta_time;
}
}
今度は SoA での処理を見てみましょう。これは今回使用する反復コードです。
voidPhysicsSystem::SimulateObjects(constfloat delta_time )このコードでは 2 つのキャッシュミスが即座に発生しますが、その次の 2 つのキャッシュミスが発生する前におよそ 5.3 回の反復処理をスムーズに実行できるため、パフォーマンスが大幅に向上します。
{
for(int i =0; i < mNumObjects;++i )
{
mPositions[ i ]+= mVelocities[i]* delta_time;
}
}
重要なのはハードウェアにデータを送信する方法です。データ指向設計に留意し、オブジェクト指向コードよりも効率的に実行される場所を探しましょう。
ここで紹介したのはほんの一例です。データ指向プログラミングには、オブジェクトの構造化以上に重要な点が多くあります。たとえば、キャッシュは命令や関数のメモリの格納に使用されるため、関数やローカル変数を最適化するとキャッシュミスやキャッシュ ヒットに影響を及ぼします。また、L2 キャッシュや、データ指向設計でアプリケーションのマルチスレッドを容易にする方法についてもここでは説明していません。
コードをプロファイルして、データ指向設計の実装対象を確認するようにしてください。NVIDIA Tegra System Profiler、ARM Streamline Performance Analyzer、Intel、PowerVR PVRMonitorなど、アーキテクチャに応じて異なるプロファイラを使用できます。
キャッシュ用に最適化する方法の詳細については、各 CPU アーキテクチャのキャッシュ プリフェッチに関する記事をお読みください。
Posted by Yuichi Araki - Developer Relations Team